Introduction
Even Google has officially announced that it tolerates several identical sites. That is, you can have several identical websites and still retain your position in their search engine. Secondly, the world is full of plagiarism and that's completely normal. Just as people transmit information to each other (and viruses), websites do the same.
Now the question arises, how to extract certain details from a website to place them on another?
Preparing and Writing Code to Extract Details from Web Pages
For this tutorial, I will use Python because it is simple and easy to apply. My working environment is Windows 10, and I open Python scripts in Visual Studio Code. I also use geckodriver to manage the Firefox web browser.
First, you need to install Python, add the path to the bin folder in Path, and restart your computer. Create a folder that you can name whatever you like. Start VS Code and open that folder in it. Add a start.py file in it and click on the status bar at the bottom left to select the current Python installation. Also, VS Code will offer to install recommended extensions, do it, you will need them (ms-python.python).
The site whose details we will extract is https://stackoverflow.com/jobs. Copy geckodriver.exe into the same folder where you created start.py. Add the following import directives in the header:
from selenium import webdriver import time, random
import directive allows Python to use some pre-made class libraries that make programming easier (as you will see best in this example). However, some of these libraries do not come with the Python installation, but need to be additionally installed. To avoid you having to fiddle and search for these libraries on the internet, there is the pip program for that. Open the command line and type pip install selenium to install the selenium library, do the same for all other libraries you do not have on your computer.
wait_from = 4 wait_to = 8
These two variables will define the range in seconds that the script will wait after opening the page. We do not want to load pages too quickly because it is possible that the site is configured to block us otherwise.
browser = webdriver.Firefox()
browser.get("https://stackoverflow.com/jobs")
Here we have defined that we want to control Firefox and open this page first. When the page opens, it will look like this:
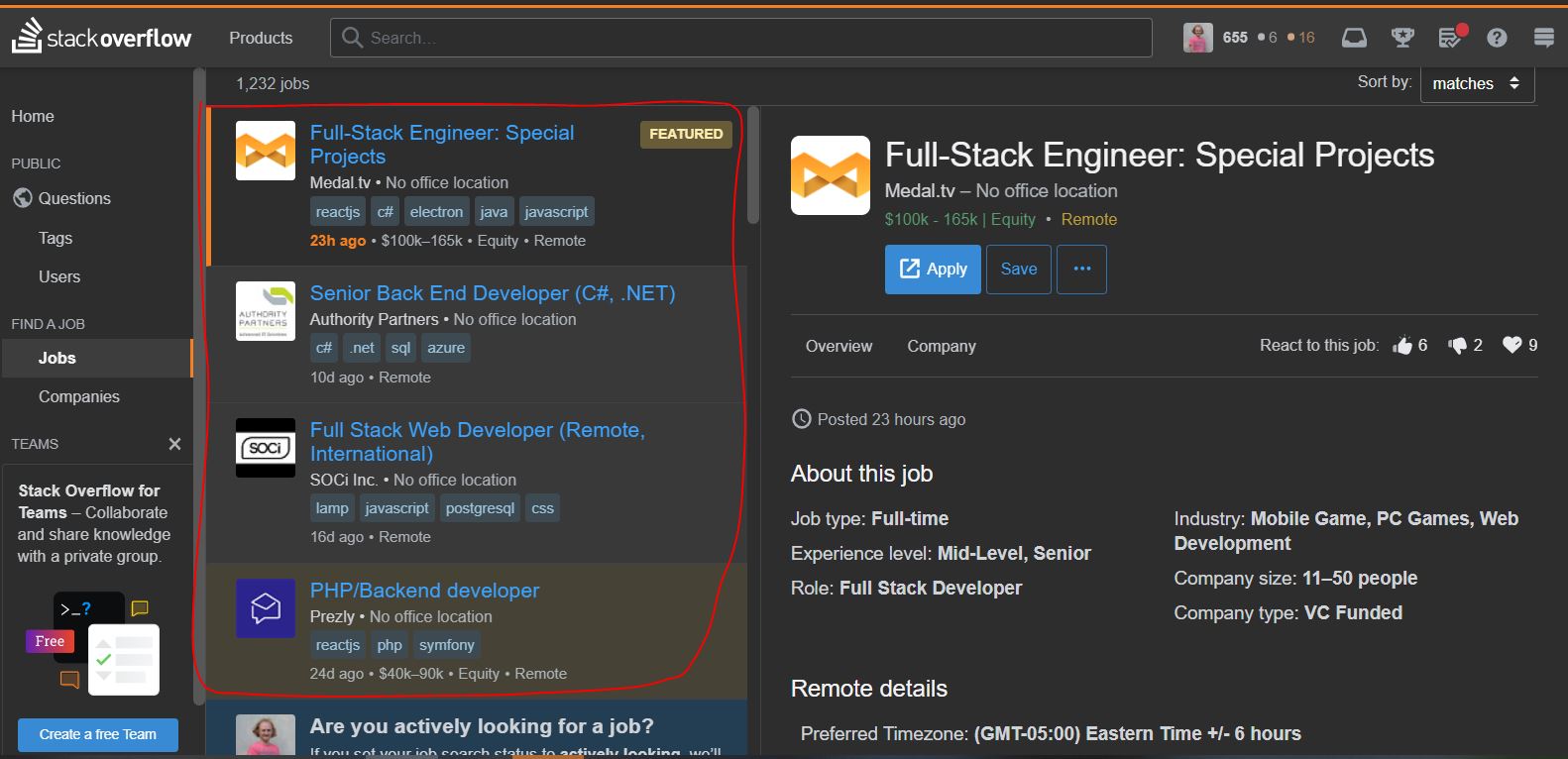
Our goal is to extract the title of each job, but there are several pages. Our aim is to navigate through these pages and extract job titles until the last page.
with open("stackoverflow-jobs.txt", "w") as txt_file:
txt_file.write("stackoverflow jobs\n")
txt_file.flush()
The next thing we will do is open a file where we will record those job titles. After that, we can work on extracting the job description text from the first page we opened.
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
browser is the active browser window we are controlling. els is an array of elements that we populate using the find_elements_by_css_selector function. This function takes a CSS selector as a parameter. By examining the source code, I see that it is ideal to use the a.stretched-link selector. I also see that the HTML title attribute is exactly what we need, and I record that in a file. Next, we need the following page, which we will reach by clicking on the number 2 in the pagination row, like this:
i = 1
found = True
while found:
i += 1
els = []
els = browser.find_elements_by_css_selector('a.s-pagination--item > span')
found = False
for span in els:
if span.text == str(i):
found = True
i is needed as a page counter to take each subsequent page. found will be used to exit the infinite loop. Looking at the source code of the page, I see that a.s-pagination--item > span is the selector for the span containing the page numbers. I return that array to els and compare it with the page I expect, and when I find it:
browser.execute_script( "arguments[0].parentNode.click();", span)
time.sleep(random.randint(wait_from, wait_to))
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
txt_file.flush()
break
I use the execute_script function, which will execute JavaScript code. This function also takes a parameter in the form of an HTML element, which is ideal in this case. I call the click method on the anchor (parentNode). Then we wait for some time for the page to load (this time can be more or less depending on the page loading speed). Next, I repeat the same procedure for extracting text as before this loop.
The whole code:
from selenium import webdriver
import time, random
wait_from = 4
wait_to = 8
browser = webdriver.Firefox()
browser.get("https://stackoverflow.com/jobs")
with open("stackoverflow-jobs.txt", "w") as txt_file:
txt_file.write("stackoverflow jobs\n")
txt_file.flush()
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
i = 1
found = True
while found:
i += 1
els = []
els = browser.find_elements_by_css_selector('a.s-pagination--item > span')
found = False
for span in els:
if span.text == str(i):
found = True
browser.execute_script( "arguments[0].parentNode.click();", span)
time.sleep(random.randint(wait_from, wait_to))
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
txt_file.flush()
break
print ("Done!")
Is it possible to easily extract website details?
Today it is very easy to program and extract details from a website. In this example, Python was used, but the same applies to PHP, C#, and other programming languages. I hope this short guide was helpful to you, and please leave a comment in the field below. Thank you for your attention and time!
If you're looking for top-tier software developer to hire, look no further!
✨ What I offer:
- Website Development: Turn your idea into a fully functional website.
- Mobile App Creation: Reach your audience on every device.
- Custom Software Solutions: Software tailored to your business needs.
- Database Management: Ensure your data is structured, secure, and accessible.
- Consultations: Not sure where to start? Let's discuss the best tech solutions for your goals.
With 20+ years of experience in the tech industry, I've honed my skills to provide only the best for my clients. Let's turn your vision into reality. Contact me today to kick off your next digital project!
Leave a Comment